
一 引言
作为目前世界上最大的汽车消费市场,中国已经成为各大汽车品牌群雄逐鹿的主战场。截止2016年8月,中国市场在售的汽车产品主品牌有127个,汽车车系783个,在售车型达到4349款[1]。中国市场是国产汽车品牌发展壮大的根据地,越来越多的国际汽车品牌将中国视为再续辉煌或者东山再起的依托市场。大量的汽车品牌与车型意味着激烈的市场竞争。有效的市场竞争分析是企业战略管理、产品研发和市场营销等活动的基础,对企业的生存和发展至关重要。


图一 汽车品牌与竞争示意图
竞争关系识别和竞争关系量化是市场竞争分析的主要内容。宏观层面的竞争关系识别通过竞争子市场划分分析整体市场的竞争结构,而微观层面的竞争关系识别主要告诉管理者谁是品牌和产品的主要竞争者。竞争关系量化则可回答不同对手之间存在多大程度的竞争,基于定量指标对产品竞争进行更加精确的度量。
包括汽车行业在内,传统的行业竞争分析主要基于访谈、问卷调研等形式收集消费者或者行业专家的认知数据。这些自我报告的认知数据虽然可以为竞争分析提供一定依据,但是存在数据获得困难、代表性较差以及无法反应消费者购买决策中的真实认知等问题。此外,传统的数据收集形式对访谈和问卷调研的过程有着严格的要求,不严谨的访谈和问卷调研过程容易使得竞争分析产生严重的偏差。因此,我们需要探索新的数据源,在此基础上设计新的竞争分析方法。
二 大数据驱动的市场竞争分析
近年来,随着新兴信息技术的广泛应用,搜索引擎日志和产品评论等数据在市场竞争分析中得到了越来越多的应用。与访谈和问卷数据的“事后”或者“事前”感知相比,在线数据记录着消费者在购买决策过程中对不同产品的对比和评价,因此能够更加准确的反映产品之间的竞争关系。
管理学顶级期刊Marketing Science、Journal of Marketing和Information Systems Research等近年来发表了多篇基于搜索引擎和在线评论数据进行市场竞争分析的研究成果[2-4]。例如,Ringel和Skiera基于56个品牌1124个产品的搜索数据研究了竞争市场识别和竞争关系可视化等问题[3]。Nam等从产品的社会化标签(Social Tags)中挖掘用户关注的品牌特征,构建了基于特征的品牌竞争关系图[4]。为了对不同产品之间的竞争度进行分析,清华大学卫强教授等人提出了基于二部图模型的非对称性竞争分析方法,该方法利用搜索记录中的产品及其特征数据构建二部图模型,对产品之间的竞争度进行度量[5]。将在线评论数据应用于汽车市场竞争分析,Netzer等将在一条在线评论中同时出现的多个汽车产品视为竞争产品,研究了基于产品共现(Co-Occurrence)的竞争度(相关度)计算方法[6]。基于汽车产品之间的竞争度,该研究成果将30个汽车品牌细分到了3个竞争市场。

图二 评论数据中蕴含的产品竞争关系
三 收藏大数据驱动的汽车产品非对称竞争识别与度量
为了对汽车产品的市场竞争进行分析,我们首次将收藏大数据(Big Favorite Data)引入汽车产品竞争分析。为了帮助用户记录感兴趣的车型,方便用户在不同车型之间进行对比分析,网易汽车、搜狐汽车和Autotrader.com等汽车论坛均提供了车型收藏的功能。在做出正式购买决策之前,消费者通常会将多个候选产品加入收藏列表,并在价格、促销、社交影响等因素的影响下从上述候选产品中做出最终的选择。产品收藏通常是基于大量信息搜索和社交互动的结果,是产品搜索到购买决策的过渡阶段。因此,与搜索引擎数据和在线评论数据相比,收藏大数据可以更好的反映产品之间的竞争关系。
图三 收藏数据中蕴含的产品竞争关系
在我们的研究中,非对称竞争主要包括三个方面:(1)市场结构的非对称性。与传统研究将产品划分到互不重叠的竞争子市场不同,我们将汽车产品划分到相互重叠的子市场中。一个车型可以在多个竞争子市场中与其他车型进行竞争。在某一子市场中互为竞品的车型,在其他市场则可能并不存在竞争关系。这一点更加符合市场竞争实际,与传统竞争分析有着很大差异。(2)产品代表性的非对称性。在特定的竞争子市场中,不同车型之间的代表性也是不一样的。由于各个竞争子市场关注的产品特征不同,某一子市场的代表性车型在其他子市场则不一定具有代表性。我们的研究可以计算每一款车型在不同子市场的代表性程度。(3)竞争网络的非对称性。市场结构的非对称性和产品代表性的非对称性决定了竞争网络的非对称性。竞争网络的非对称性主要是指某一车型到竞争对手的竞争度,不等于竞争对手到该车型的竞争度。
为了对非对称的市场结构进行划分,对非对称的代表性产品进行识别,我们提出了基于贝叶斯非参主题模型的竞争子市场识别方法。该模型具有如下两方面的优点。(1)在中国市场的几千个车型中,到底会形成多少个竞争子市场?即使经验丰富的管理者也难以给出准确的答案。因此,我们采取非参模型的思路让数据说话,基于用户收藏大数据确定最终的竞争子市场的数量。(2)传统的主题模型建立在长文本基础之上,假设一个主题的概率分布于所有的词。在汽车产品竞争分析中,用户收藏列表的长度通常很短(服从幂律分布),传统主题模型也会导致所有的车型均按一定概率出现在所有的竞争子市场。与中国市场的几千个车型相比,特定竞争子市场中的车型数量肯定非常有限,因此,主题模型的上述假设应用于汽车市场的竞争分析显然是不合理的。针对上述问题,我们均提出了相应的解决方法。
为了形成非对称的竞争网络,我们利用得到的非对称竞争市场结构构建基于车型和竞争子市场的二部图模型。在此基础上,设计了基于随机游走算法的竞争度计算方法。我们的研究可以考虑车型到竞争子市场的隶属关系、不同车型在竞争子市场的代表性、以及竞争子市场在整体汽车市场中的流行度等因素,对车型之间的直接竞争和非直接竞争进行量化。
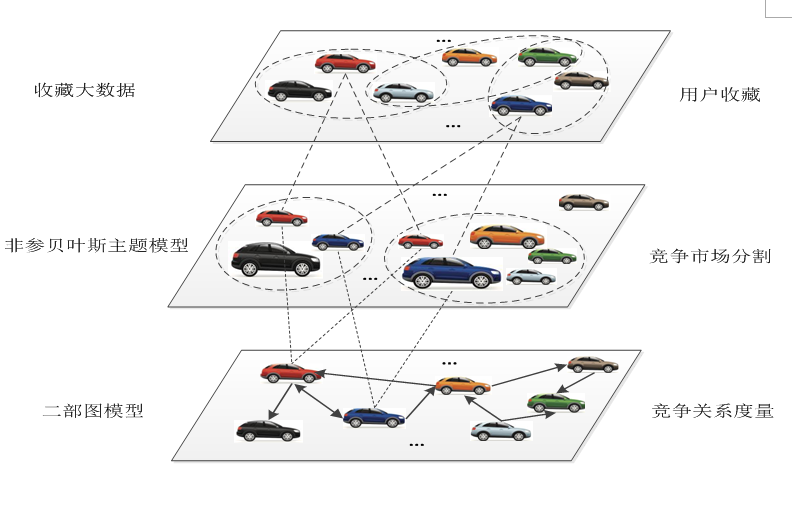
图四 模型结构
四 结论与展望
基于包含200+个品牌、2000+款车型和15万+个收藏列表的数据,我们将中国的汽车市场分成90+个竞争子市场,每个竞争子市场评价包含90+款车型,最大的竞争子市场包括150+款车型。由于我们的模型允许一个车型在多个子市场进行竞争,每个车型平均在5个左右的子市场出现。被誉为“国民神车”的哈弗H6在多达50+个竞争子市场出现。在汽车整体市场中,各竞争子市场具有不同的流行度。我们的研究表明,虽然部分子市场具有较高的流行度,接近50%的竞争子市场流行度很低。大量小众市场的存在实际上也蕴含着诸多的差异化竞争的机会。
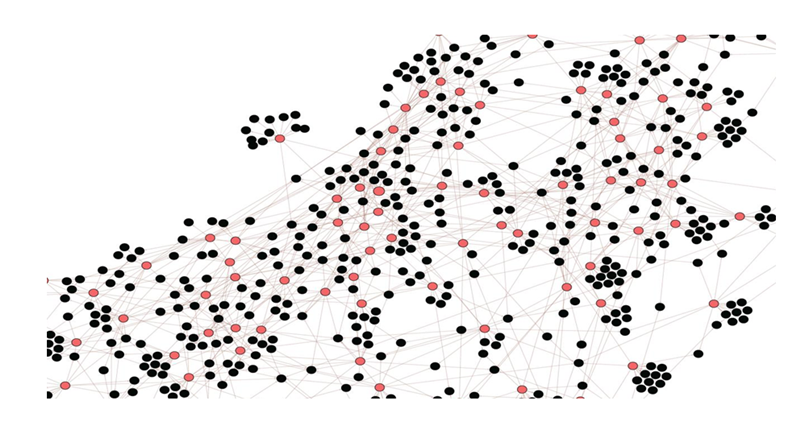
图五 竞争市场结构划分(红点表示竞争子市场,黑点表示子市场所包含的车型)
我们发现不同竞争子市场内部的竞争也存在较大的差异。在图六(a)子市场中,虽然该子市场包含多种车型,但是,五菱宏光和宝骏730的代表性与其他车型具有显著差异。图六(b)子市场中则不存在这样的典型代表车型,不同车型的代表性差别不大。此外,虽然五菱宏光在(a)子市场中的代表性具有较大优势,在(b)子市场中其竞争优势则不是那么明显。基于收藏数据,我们可以计算出每一款车型在不同竞争市场中的代表性程度。
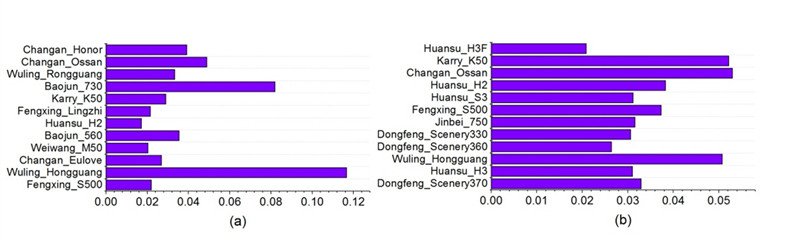
图六 竞争子市场中的代表性车型
车型之间的差异化竞争在我们的结论中也得到了很好的验证。以林肯MKZ和奔驰C系为例,奔驰C对林肯MKZ的竞争度为0.026,而林肯MKZ对奔驰C的竞争度仅为0.0024。这种非对称性说明,林肯MKZ的潜在消费者很有可能同时考虑是否购买奔驰C。但是,奔驰C的潜在消费者则较少地考虑林肯MKZ,他们会更多的考虑宝马3和奥迪A4L等奔驰C的竞争车型。基于随机游走的二部图模型为汽车产品之间竞争程度的度量提供了理论依据。
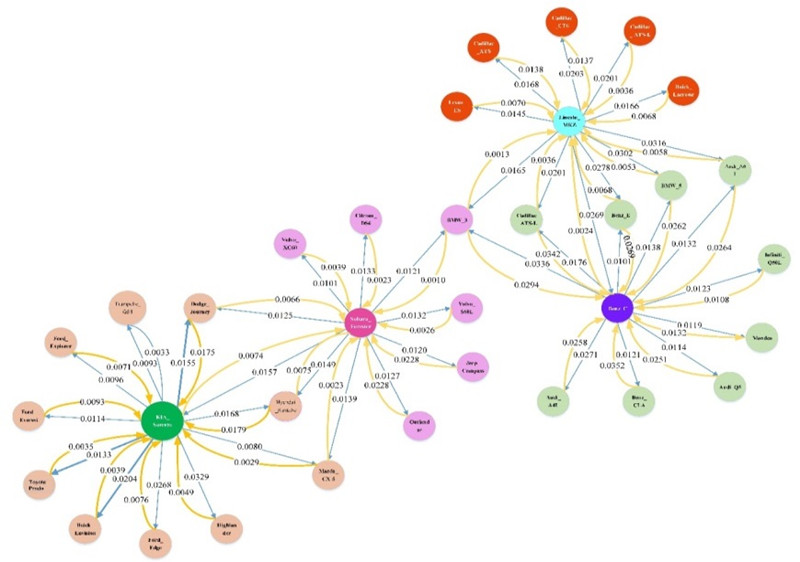
图七 非对称竞争网络图
近年来,大数据驱动的管理与决策已经成为管理领域研究的主流范式。我们需要面向管理问题,关联多维大数据,创新研究方法,从新的视角和新的粒度得到新的管理启示。在大数据驱动的汽车市场竞争分析中,集成收藏数据、标签数据、评论(情感)数据、社交数据,从消费者的视角,将市场竞争分析细分到网络社区直至消费者个体,对整体市场划分、竞争子市场分析和产品竞争关系度量等问题进行分析,仍需进一步探索。
参考文献:
[1] 搜狐汽车,数字汽车独家数据:中国汽车市场到底有多少种车型,www.sohu.com/a/115926134_514621
[2] Pant, G., & Sheng, O. R. (2015). Web footprints of firms: Using online isomorphism for competitor identification. Information Systems Research, 26(1), 188-209.
[3] Ringel, D. M., & Skiera, B. (2016). Visualizing asymmetric competition among more than 1,000 products using big search data. Marketing Science, 35(3), 511-534.
[4] Nam, H., Joshi, Y. V., & Kannan, P. K. (2017). Harvesting Brand Information from Social Tags. Journal of Marketing (Forthcoming).
[5] Wei, Q., Qiao, D., Zhang, J., Chen, G., & Guo, X. (2016). A Novel Bipartite Graph Based Competitiveness Degree Analysis from Query Logs. ACM Transactions on Knowledge Discovery from Data (TKDD), 11(2), 21(1-25).
[6] Netzer, O., Feldman, R., Goldenberg, J., & Fresko, M. (2012). Mine your own business: Market-structure surveillance through text mining. Marketing Science, 31(3), 521-543.
作者简介:
姜元春,山东莱西人,1980年生,电子商务系主任,副教授。近年来一直从事电子商务、个性化营销和数据挖掘等方面的理论研究工作。先后主持国家自然科学基金优秀青年基金、国家自然科学基金重大研究计划培育项目、国家自然科学基金青年基金、教育部人文社科基金、高等学校博士点基金(新教师类)、阿里巴巴青年学者支持计划、腾讯CCF-犀牛鸟计划等课题的研究工作。在营销领域国际权威期刊Marketing Science、软件工程领域国际权威期刊IEEE Transactions on Software Engineering以及Decision Support Systems、Information Sciences、International Journal of Production Research、International Journal of Production Economics等国内外学术期刊发表研究论文,获国家发明专利授权4项,参与出版学术专著3部,获高等学校科学研究优秀成果奖(自然科学奖)二等奖1项(排名第四)。
